Capítulo 8 Bosques aleatorios de decisión
Si aplicamos de manera iterativa el algoritmo que crea árboles de decisión con diferentes parámetros sobre los mismos datos, obtenemos lo que denominamos un bosque aleatorio de decisión (random forest). Este algoritmo es uno de los métodos más eficientes de predicción y más usados hoy día para big data, pues promedia muchos modelos con ruido e imparciales reduciendo la variabilidad final del conjunto.
En realidad lo que se hace es construir diferentes conjuntos de entrenamiento y de test sobre los mismos datos, lo que genera diferentes árboles de decisión sobre los mismos datos, la unión de estos árboles de diferentes complejidades y con datos de origen distinto aunque del mismo conjunto resulta un bosque aleatorio, cuya principal característica es que crea modelos más robustos de los que se obtendrían creando un solo árbol de decisión complejo sobre los mismos datos.
El ensamblado de modelos (arboles de decisión) distintos genera predicciones mas robustas. Los grupos de árboles de clasificación se combinan y se deduce una única predicción votada en democracia por la población de árboles.
El paquete randomForest en R nos permite crear este tipo de modelos de manera muy sencilla.
8.1 Ejemplo de bosque aleatorio
Vamos a utilizar los datos de supervivientes del Titanic para crear un bosque aleatorio. La tabla origen la creamos a partir de la muestra de datasets como vimos en el apartado de particiones de los datos.
Tenemos un conjunto de entrenamiento almacenado como d_titanic_train. En esta muestra no hay NA, pero si los datos contuviesen NA habría que imputar o quitar los registros antes de ejecutar el modelo, por ejemplo con complete.cases(d_titanic_train)
# Cronstuir un bosque de decisión
library(randomForest)## randomForest 4.6-14## Type rfNews() to see new features/changes/bug fixes.#creamos el modelo
m <- randomForest(Survived ~ .,
data = d_titanic_train[complete.cases(d_titanic_train),],
ntree = 100 # numero de arboles en el bosque
)
plot(m) # pintamos evolucion de arboles del modelo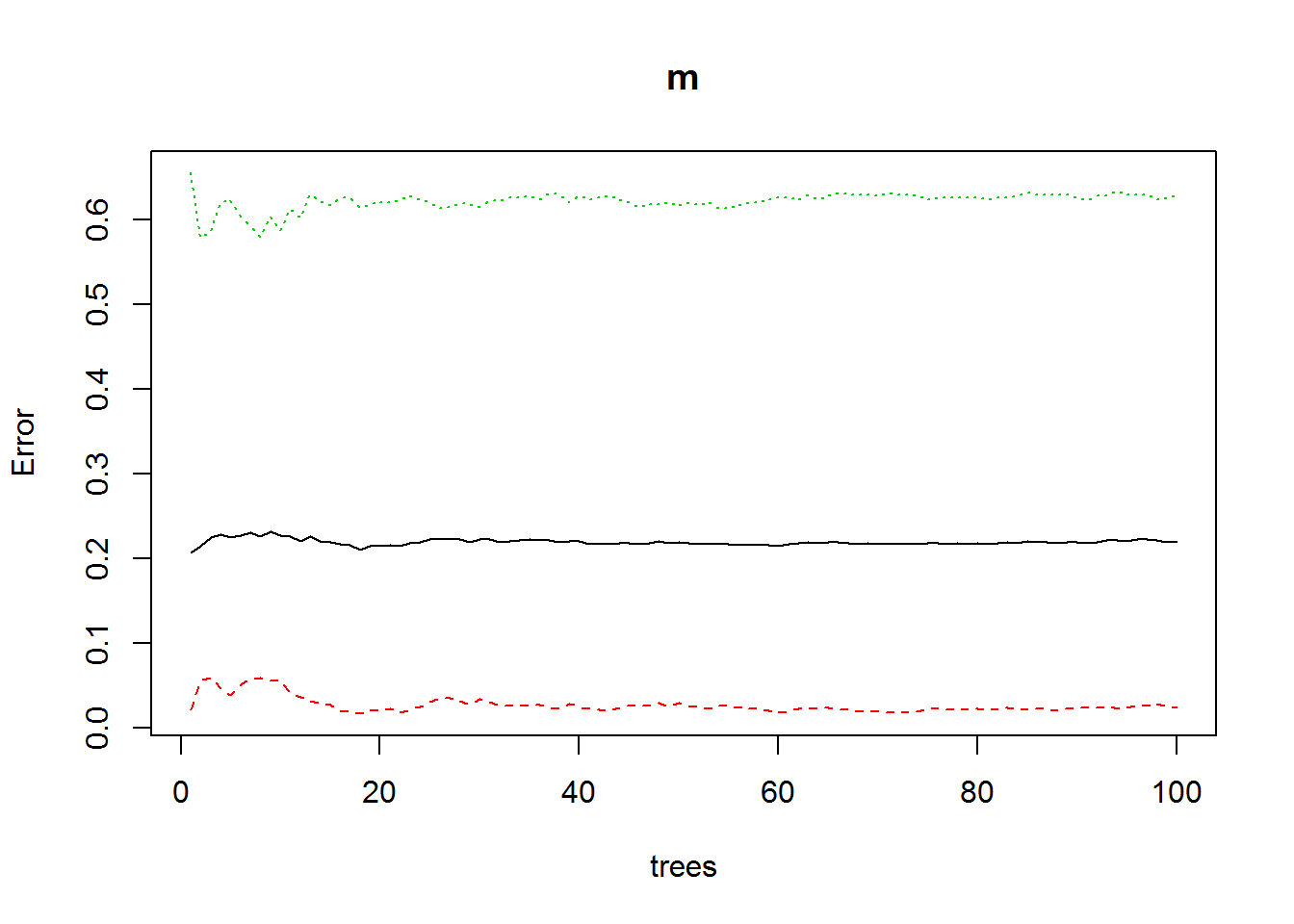
# borramos predicciones anteriores
d_titanic_test$pred<-NULL
d_titanic_test$pred_final_60<-NULL
d_titanic_test$pred_final_40<-NULL
#titanic_test$p<-NULL
# Hacemos las predicciones y las almacenamos en la col p.
d_titanic_test$pred <- predict(m, d_titanic_test)
levels(d_titanic_test$pred)<- c(0,1) # cambiamos los levels como hicimos en apartado 1
# calculamos la bondad de la prediccion
# mean(d_titanic_test$pred == d_titanic_test$Survived)
# vemos los datos
head(d_titanic_test,10)## Class Sex Age Survived pred
## 3.3 3rd Male Child No 0
## 3.14 3rd Male Child No 0
## 3.15 3rd Male Child No 0
## 3.16 3rd Male Child No 0
## 3.21 3rd Male Child No 0
## 3.23 3rd Male Child No 0
## 3.24 3rd Male Child No 0
## 3.30 3rd Male Child No 0
## 3.32 3rd Male Child No 0
## 3.34 3rd Male Child No 0